准备工作
作为 Swift 开发者,一定对 Dictionary (字典) 非常熟悉。如果你也是一个 Kotlin 开发者,那会对 HashMap 有所了解。这两种数据结构的本质都是 hash table (哈希表)。
Swift 中的字典是一个键值对集合。想要在字典中存储一个值,需要通过 key 来传递:
var dictionary: [String: String] = [:]
// 添加 键值对
dictionary["firstName"] = "Steve"
// 通过 key 获取值
dictionary["firstName"] // 输出 "Steve"
实际上,字典将键值对存入一个哈希表。本文中,你将了解到哈希表的一个基础实现以及它的性能。
哈希表
哈希表在本质上其实就是一个数组。初始化时,数组为空。当你通过某个键将一个值存放到哈希表的时候,哈希表会通过键计算出对应的数组下标。举个例子:
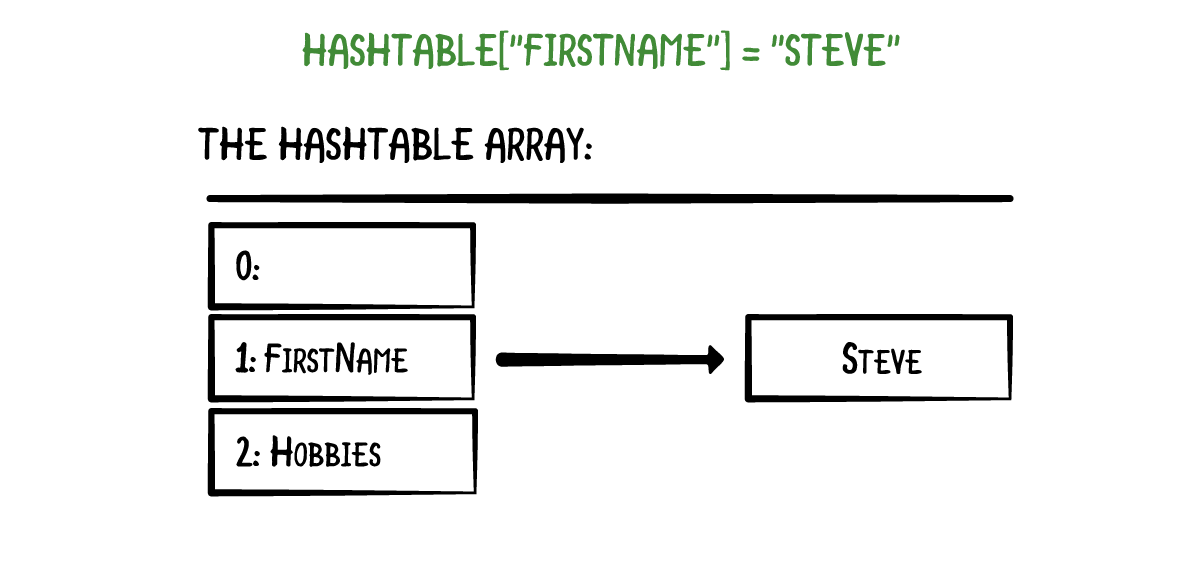
上述的例子中,键 "firstName" 印射到了数组下标 1。
使用不同的键来添加一个值,会被放入另一个数组下标中:
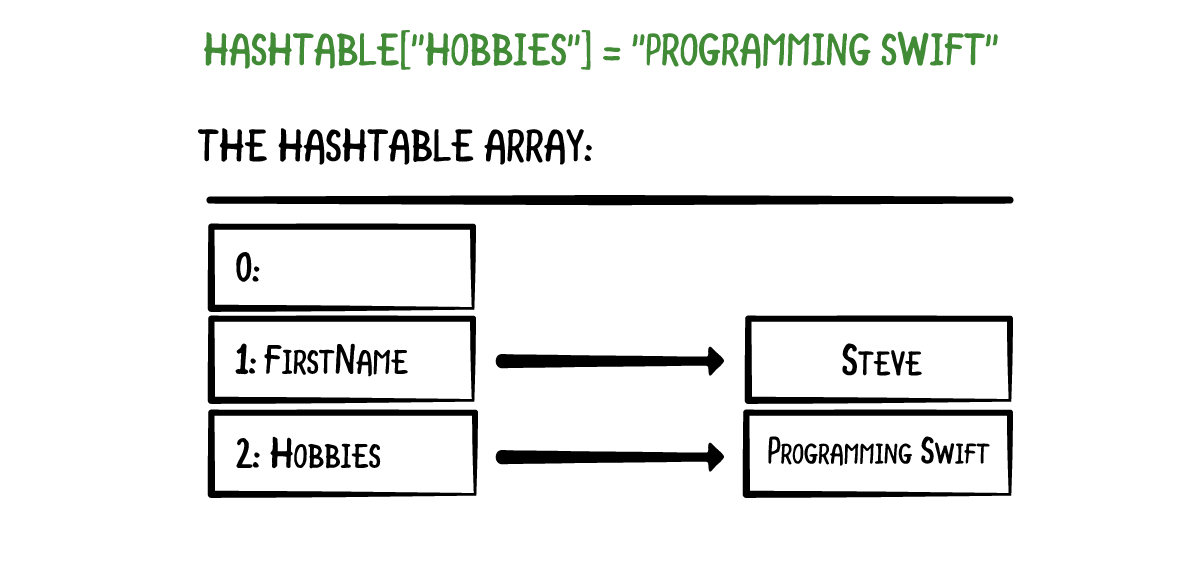
关键在于哈希表是如何计算出这些数组下标的。这就是哈希算法的由来了。有如下声明代码,
hashTable["firstName"] = "Steve"
哈希表得到键 “firstName” 并且调用它的 hashValue 属性。因此,键必须遵循 Hashable 协议。
哈希函数
当你调用 "firstName".hashValue,会得到一个整数:-8378883973431208045。同样地,"hobbies".hashValue 的哈希值为:477845223140190530。
哈希值是 hash function (哈希函数) 的计算结果,哈希函数接收一个输入参数并且返回一个整数:
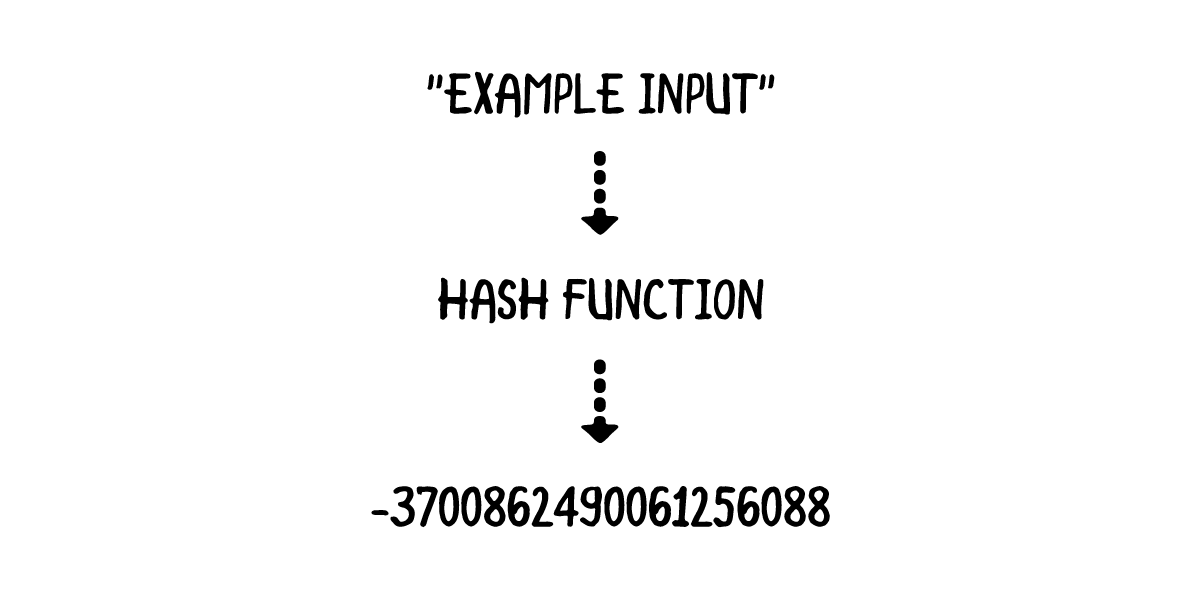
为了更好的理解哈希函数是如何工作的,你将实现两个简单的哈希函数。打开一个 playground 新增如下代码:
func naiveHash(_ string: String) -> Int {
let unicodeScalars = string.unicodeScalars.map { Int($0.value) }
return unicodeScalars.reduce(0, +)
}
上述哈希函数中,将字符串中的每个字符的 Unicode scalar 值累加。接下来在 playground 中添加如下代码。
naiveHash("abc") // 输出 294
哈希函数通过 map 一个字符串来获得一个整数值,并不是一个好的方式。为什么呢?
naiveHash("bca") // 输出 294
由于 naiveHash 只是简单的把每个字符的 Unicode scalar 值累加,任何特定字符串的不同排列都会得到相同的结果。
多把钥匙可以打开同一把锁!这并不好。一点点努力就可以让哈希函数有一个本质的提升。在 playground 中添加如下代码:
// 来源:https://gist.github.com/kharrison/2355182ac03b481921073c5cf6d77a73#file-country-swift-L31
func djb2Hash(_ string: String) -> Int {
let unicodeScalars = string.unicodeScalars.map { Int($0.value) }
return unicodeScalars.reduce(5381, {
($0 << 5) &+ $0 &+ Int($1)
})
}
djb2Hash("abc") // 输出 193485963
djb2Hash("bca") // 输出 193487083
这一次,两个排列得到了两个不同的哈希值。Swift 标准库中,String 的哈希函数要复杂的多,并且使用了 SipHash 算法。这超出了本文讨论的范畴了。
保证数组空间
"firstName" 的哈希值为 -8378883973431208045。这个值不仅很庞大,同时它还是一个负值。那么如何处理这个哈希值呢?一个普遍的做法是取它的绝对值,之后以数组长度做模运算。
在之前的例子中,数组的长度为 3。键 "firstName" 的数组下标变成了 abs(-8378883973431208045) % 3 = 1。同理可以得出 "hobbies" 的数组下标为 2。
使用哈希的方式使得字典变得更为效率。在哈希表中查找一个值,你必须取键的哈希值来获取数组的下标,接下来就是查找对应下标的数组元素了。所有的这些操作所消耗的时间都是固定的,因此,新增,查询和删除的时间复杂度都是 O(1)。
备注:由于无法预估数组的最终长度。因此,字典无法保证哈希表中元素的有序性。
避免碰撞
对哈希值做模运算也会获得相同的值,这里有个例子:
djb2Hash("firstName") % 2 // outputs 1
djb2Hash("lastName") % 2 // outputs 1
这个例子有点不自然,例子的目的在于支出哈希映射有可能指向相同的数组下标,这被称之为哈希碰撞。一个常用的解决碰撞的方法是使用链表。数组形式如下:
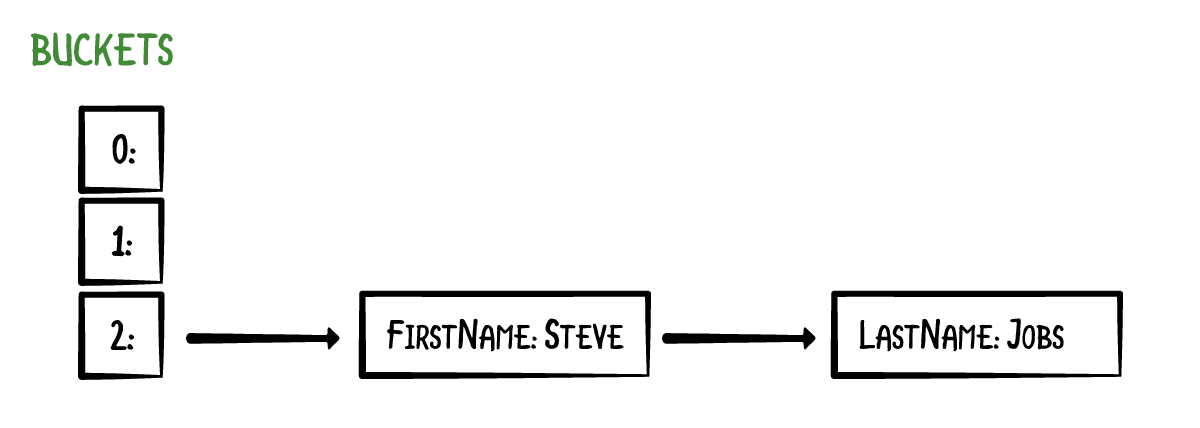
利用链表,键值对并不直接存储在数组中。取而代之的是数组中的每个元素都是一个键值对的链表。这样的数组元素称之为 buckets (桶)。
查找内容
从哈希表中获取一个值的例子如下:
let x = hashTable["lastName"]
哈希表首先计算了 "lastName" 的哈希值,并映射为数组下标为 2。由于数组下标为 2 的桶包含一个链表,就下来的步骤就是在链表中查找键值为 "lastName" 的值。链表应当限制长度,否则将会降低哈希表中的查找速度。理想情况下,并不需要链表,但实际上完全避免碰撞是不可能的。可以通过在哈希表设置足量的桶以及使用高质量的哈希函数来降低碰撞概率。
备注:一个可以替换链表的方法 “open addressing” (开放地址)。关键思想在于:如果数组中的某个下标已经被占用了,就将元素放到下一个未被使用的桶中。这个方法有它特有的优势和劣势。
代码实现
在 Source 目录下,创建 Swift 文件命名为 HashTable.swift。写入如下代码:
public struct HashTable<Key: Hashable, Value> {
private typealias Element = (key: Key, value: Value)
private typealias Bucket = [Element]
private var buckets: [Bucket]
private(set) public var count = 0
public var isEmpty: Bool {
return count == 0
}
public init(capacity: Int) {
assert(capacity > 0)
buckets = Array<Bucket>(repeating: [], count: capacity)
}
}
由于将 Key 约束为 Hashable,所以字典中的所有键都有哈希值,所以你的字典无需担心计算哈希值。哈希表中的,主要的数组命名为 buckets,并通过 init(capacity) 方法提供了固定的长度。另外可以通过 count 属性来获取存入哈希表中的元素个数。
操作类型
现在,哈希表的基础已经完成了,接下来定义一些可变方法来操作这个数据结构。一般有如下四种操作:
- 插入新的元素
- 查找某个元素
- 更新已经存在的元素
- 删除一个元素
语气的语法应该是:
hashTable["firstName"] = "Steve" // insert
let x = hashTable["firstName"] // lookup
hashTable["firstName"] = "Tim" // update
hashTable["firstName"] = nil // delete
首先,定义如下方法:
private func index(for key: Key) -> Int {
return abs(key.hashValue) % buckets.count
}
这个方法为了确保键值映射到存储数组中的下标没有越界。接下来,在 index(for:) 下面添加如下方法
查找元素
// 1
public subscript(key: Key) -> Value? {
get {
return value(for: key)
}
}
// 2
public func value(for key: Key) -> Value? {
let index = self.index(for: key)
return buckets[index].first { $0.key == key }?.value
}
subscript方法接受一个键并返回对应的值。value(for:)首先调用了index(for:)将键转换为数组下标。当出现哈希碰撞时,这个桶可能对应了多个键,因此需要比较每个元素的键和需要查找的键。
插入元素
subscript 也应当提供一个 setter 方法。在 subscript 中添加如下代码:
set {
if let value = newValue {
update(value: value, for: key)
}
}
接下来添加这里的 update(value:for:) 方法:
@discardableResult
public mutating func update(value: Value, for key: Key) -> Value? {
let index = self.index(for: key)
// 1
if let (i, element) = buckets[index].enumerated().first(where: { $0.1.key == key }) {
let oldValue = element.value
buckets[index][i].value = value
return oldValue
}
// 2
buckets[index].append((key: key, value: value))
count += 1
return nil
}
- 首先检测值是否已经存在,如果存在只需要更新对应的数组下标
i。 - 如果没有检测到,则新建一个键值对,并存入桶数组的最后。
删除元素
最后一个操作是实现删除某个键的元素操作。更新 subscript 方法:
// 1
public subscript(key: Key) -> Value? {
get {
return value(for: key)
}
set {
if let value = newValue {
update(value: value, for: key)
} else {
removeValue(for: key)
}
}
}
接下来添加 remove(value: for:) 方法:
@discardableResult
public mutating func removeValue(for key: Key) -> Value? {
let index = self.index(for: key)
// 1
if let (i, element) = buckets[index].enumerated().first(where: { $0.1.key == key }) {
buckets[index].remove(at: i)
count -= 1
return element.value
}
// 2
return nil
}
实现方法和 update 方法类似。第一步检测值是否在桶数组中。如果存在则移除键,count 做减 1 操作。如果值不存在,则返回 nil。